Advanced Machine Learning Method Development
HAIL focuses on developing statistical machine learning techniques that are at the core of modern AI. Our research generalizes real-world problems by proposing solutions grounded in cutting-edge mathematical and statistical methodologies. The ultimate goal is to create robust, highly-usable models that can be applied across a wide range of applications.
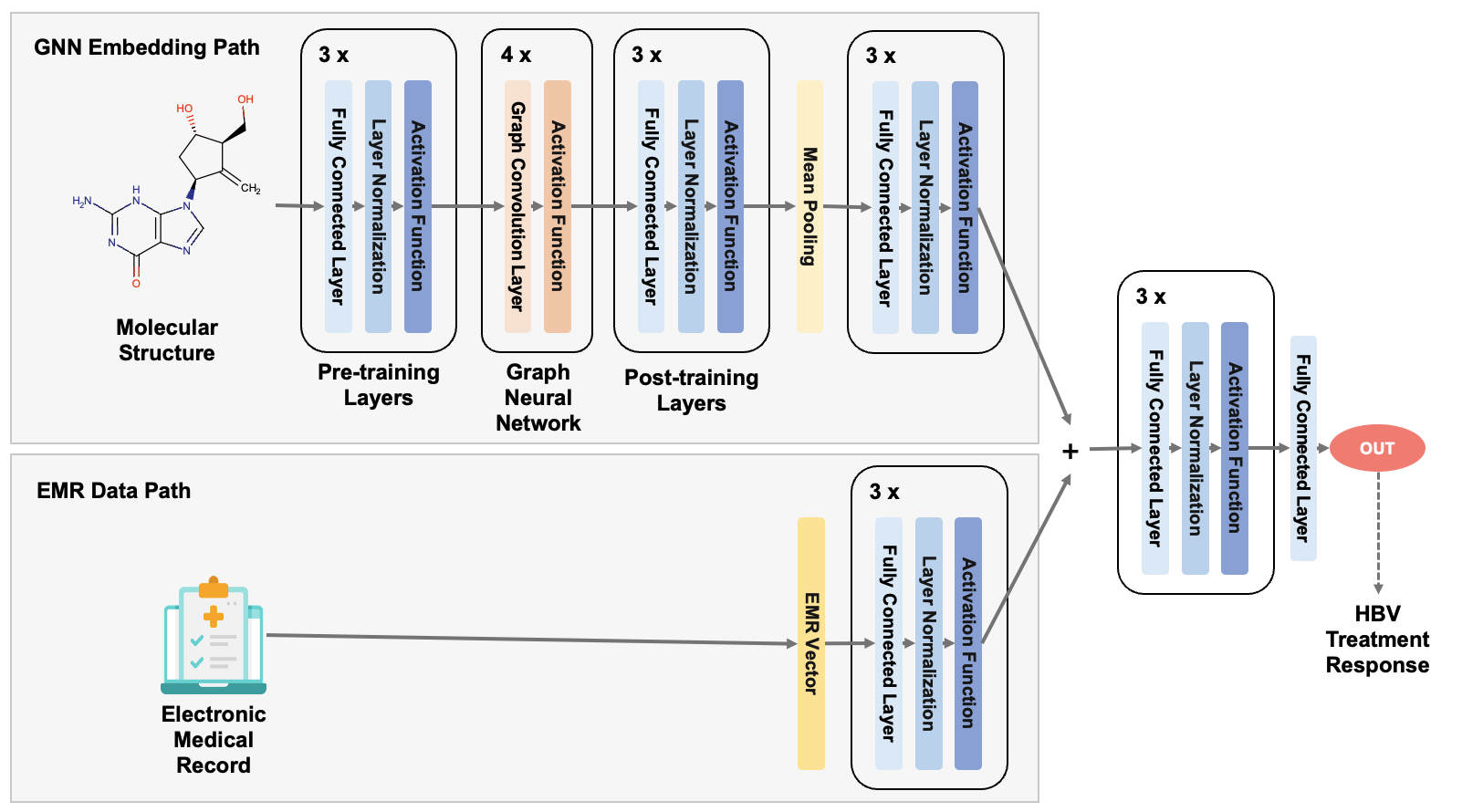
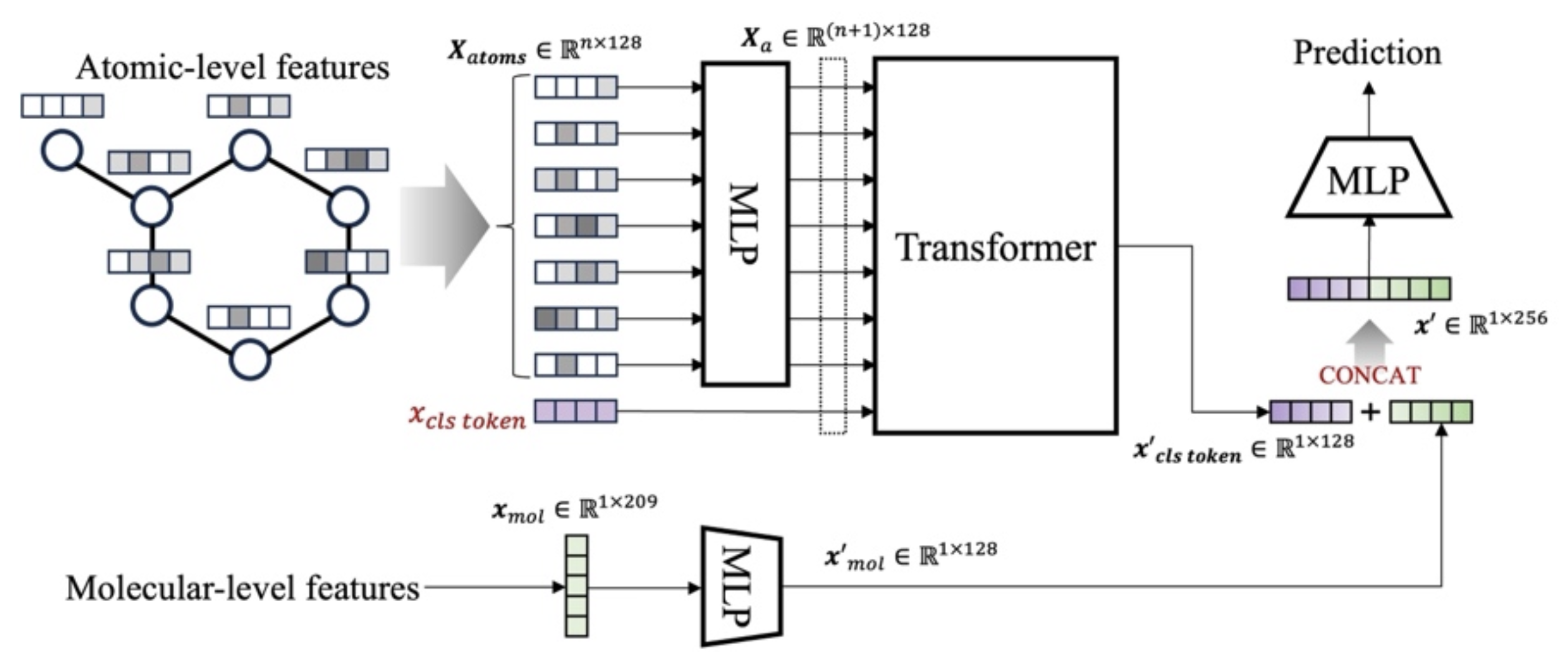
- Prediction with Graph Data: One of our longstanding research interests is exploring how to uncover the inherent structure of data and leverage it for modeling and prediction. This line of work, centered on graph neural networks and Transformer architectures, investigates multiple problems such as property prediction for molecular compounds, modeling drug responses and side effects, and generating entity embeddings through ontology structures. By advancing these methods, we aim to push the boundaries of structure-aware machine learning models, in order to handle complex data relationships effectively.
- Outlier Detection Using Transformer Models: Outlier detection, or finding the "weirdos" in a dataset, is a critical step in many data analysis pipelines. With the increasing complexity of modern data, the methods used to detect outliers are also becoming more sophisticated. Our research focuses on leveraging the power of Transformer architecture--which is widely used in natural language processing and other domains—-to develop efficient and effective methods for detecting outliers in large and complex datasets. By integrating Transformer models into outlier detection tasks, we aim to enhance the accuracy and robustness of identifying anomalies across various domains.
- Learning with Multiple Modalities: An emerging keyword in contemporary machine learning research is "multi-modal." As the research community has extensively explored how to develop models for single-modality data, attention has now shifted toward integrating multiple modalities to maximize predictive power. We focus on creating new techniques and models that can effectively blend data from different modalities—such as images and tabular data, videos and text, or time-series and image data, etc. Our goal is to design models that can seamlessly integrate these diverse data types and can extract the most relevant information to offer more precise predictions.
Medical & Clinical AI: Transforming Healthcare with AI
One of the ambitious goals of AI lies in the field of medicine. HAIL is committed to applying advanced ML technologies to healthcare in order to improve the quality of medical services and expand access to care for a greater number of people. Our work spans several cutting-edge projects that harness AI to improve patient care and clinical decision-making.
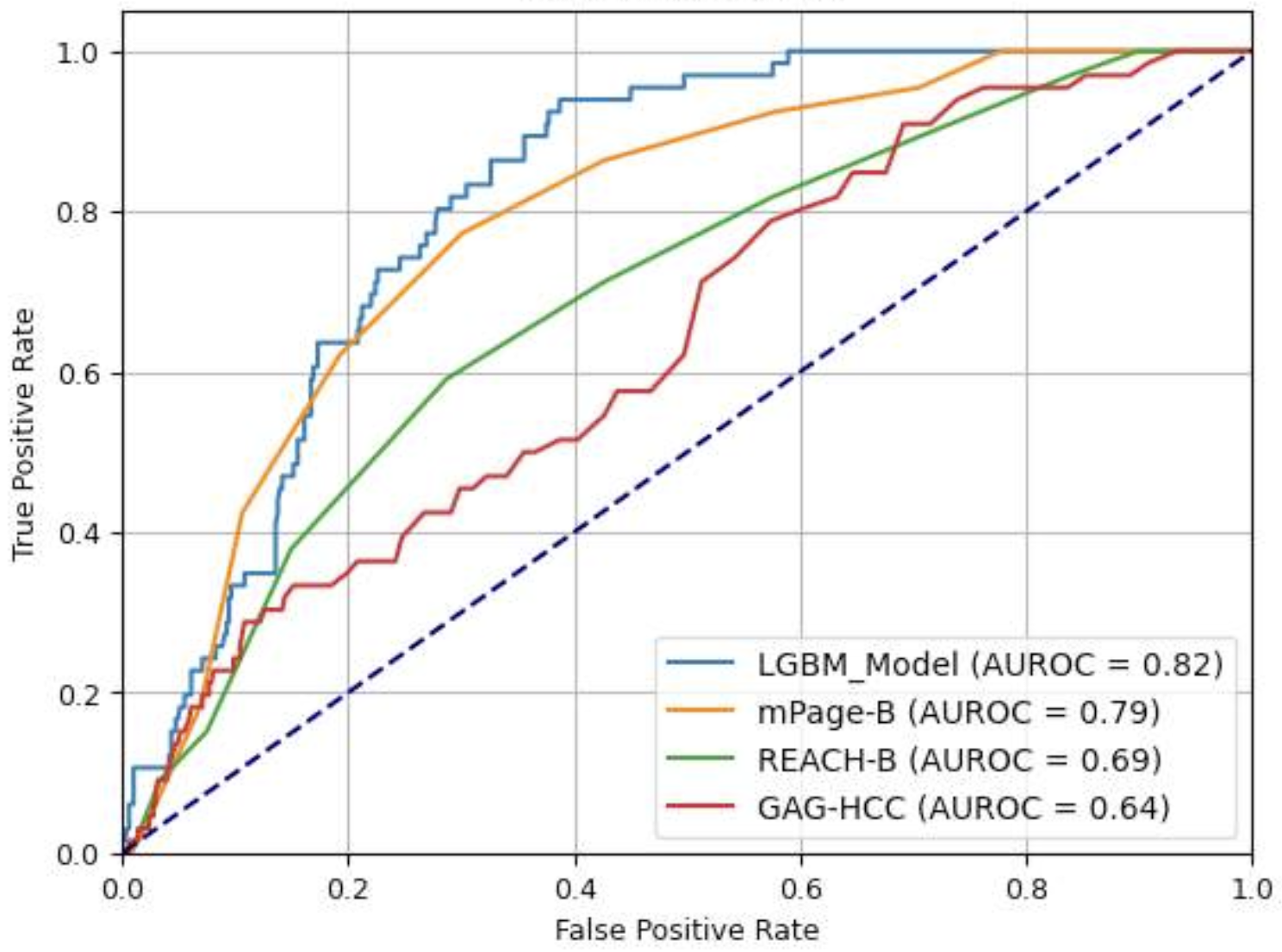
- Development of Liver Disease Support Software (with Dr. Answer 2.0 Liver Disease Team, Ajou University Hospital): Electronic medical records (EMR) serve as a hub of clinical data that captures a wealth of information about patient events. These records are a treasure trove for running intelligent medical systems. At HAIL, we are processing EMR data to enable machine learning applications, which help develop various clinical decision support solutions related to liver diseases.

- AI Algorithm for Human-Derived Specimen Image Recognition (with HEM Pharma): Human-derived specimens can provide valuable insights into a person's health status. In this project, we are developing AI algorithms that automatically process images of human specimens, for continuous health monitoring. Our solution automates the generation and comparison of machine learning models to ensure the use of up-to-date recognition models, along with continuously collected data. This approach ensures timely maintenance of the machine learning system that provides accurate health assessments.
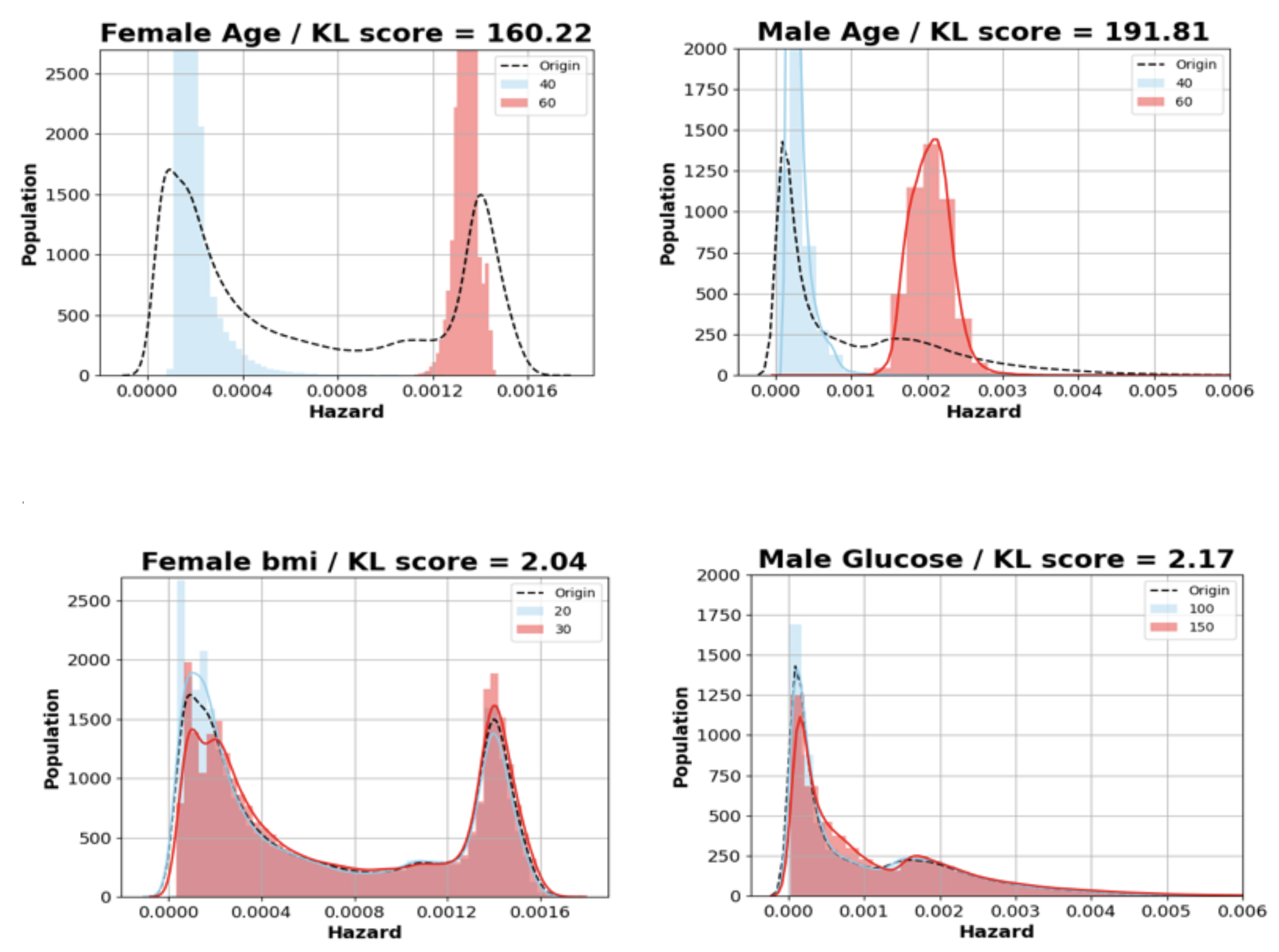
- Risk Model and Analysis for Pancreatic Cancer (with Herings): In South Korea, the National Health Insurance program mandates biennial health checkups for all citizens. Using health checkup data combined with follow-up records from the National Cancer Center on pancreatic cancer diagnoses, we have built predictive models that assess an individual's risk of developing pancreatic cancer. Our risk analysis offers the potential to identify high-risk individuals early, which in turn leads to better prevention and treatment strategies.
- Multi-Modal Healthcare Method Development (with Prof. Yuyin Zhou, UCSC): One of the next milestones in machine learning is the ability to blend data from multiple modalities to maximize available information and refine predictive models. Starting with the RadFusion dataset from the Stanford Center for Artificial Intelligence in Medicine and Imaging (AIMI), this project explores how to integrate various data modalities generated in healthcare settings, such as EMRs, imaging data, drug structures, free-text notes, and medical ontologies, into robust decision-making models. By doing so, we aim to improve the accuracy of clinical predictions and support optimal healthcare decisions.
Anomalies in Surveillance Video
With the increasing number of surveillance cameras and car dashcams, the volume of video footage generated has grown exponentially. These recordings play a critical role as foundational material in investigations when incidents occur. However, the task of reviewing and analyzing surveillance footage is still predominantly handled by human analysts, which can be highly inefficient and prone to error. To address this, we aim to develop automated methods that detect critical segments in surveillance videos using advanced computer vision techniques.
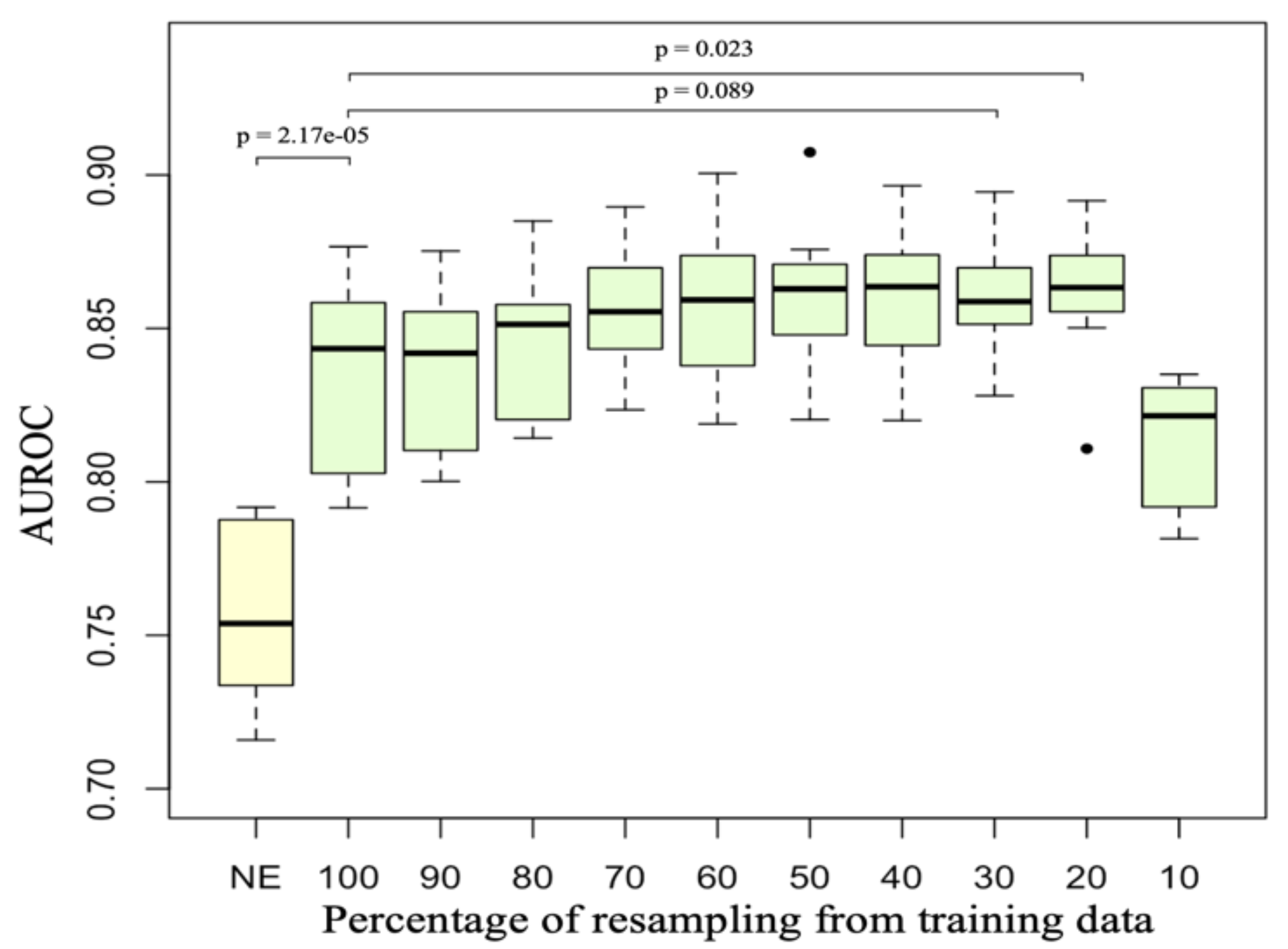
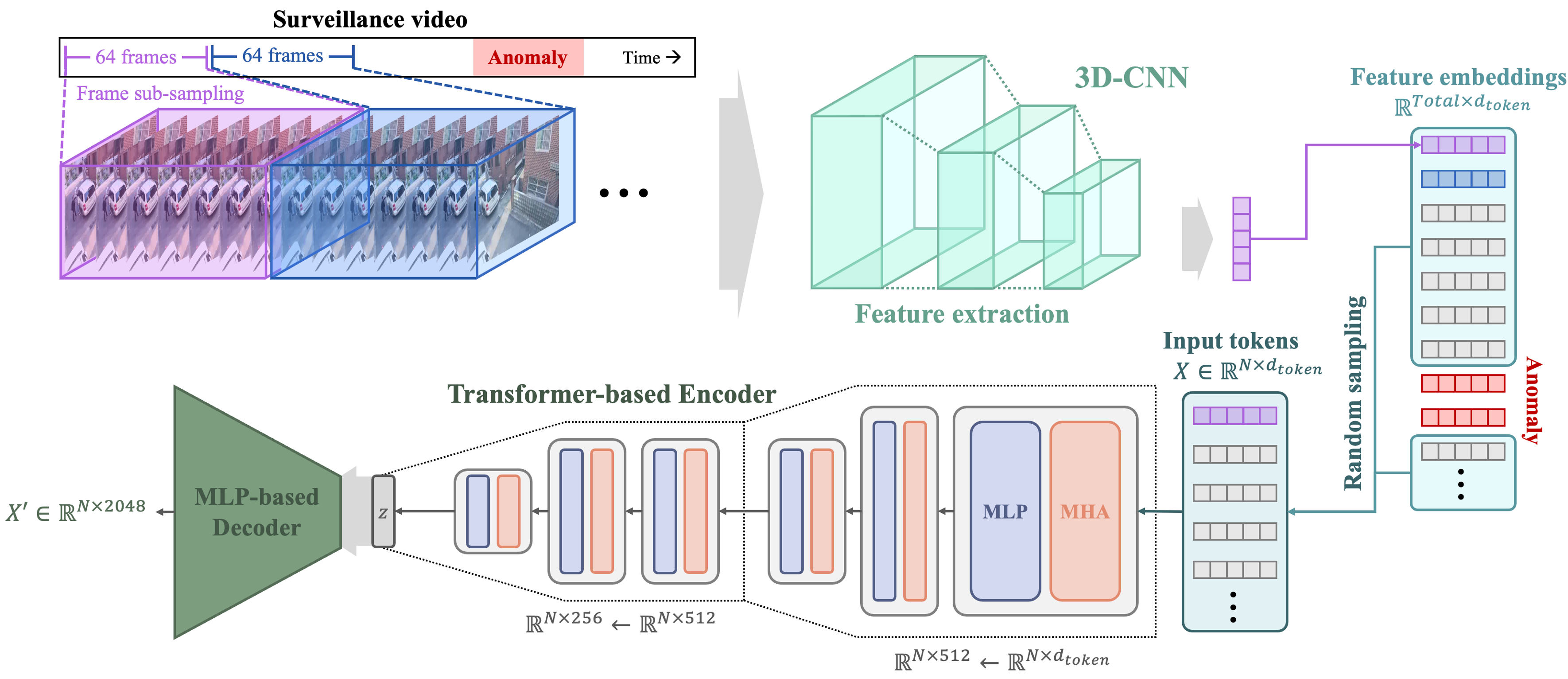
- Video Anomaly Detection with Variational Autoencoder (with GMDSOFT): In this project, we are incorporating 3D-CNNs (convolutional neural networks) and Transformer-based architectures into autoencoder structures to develop an effective method for detecting anomalies in surveillance camera footage. Our approach has achieved state-of-the-art performance and has been presented at leading venues.

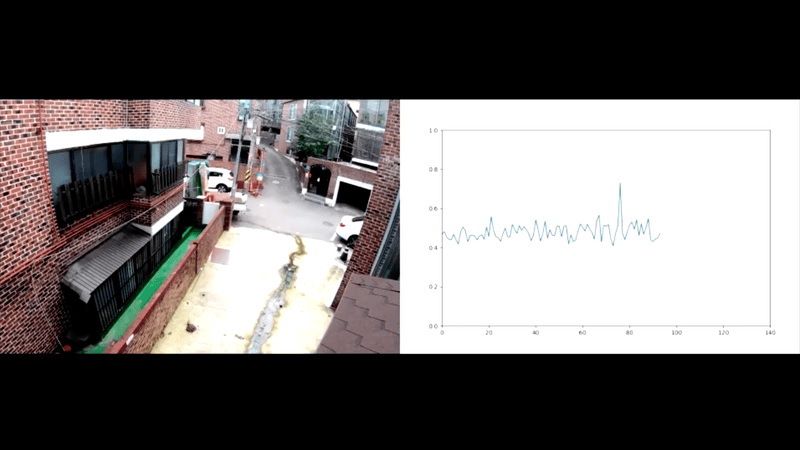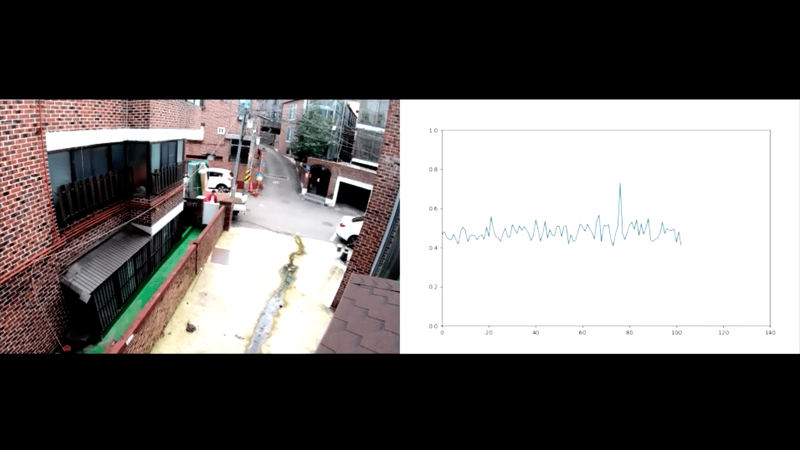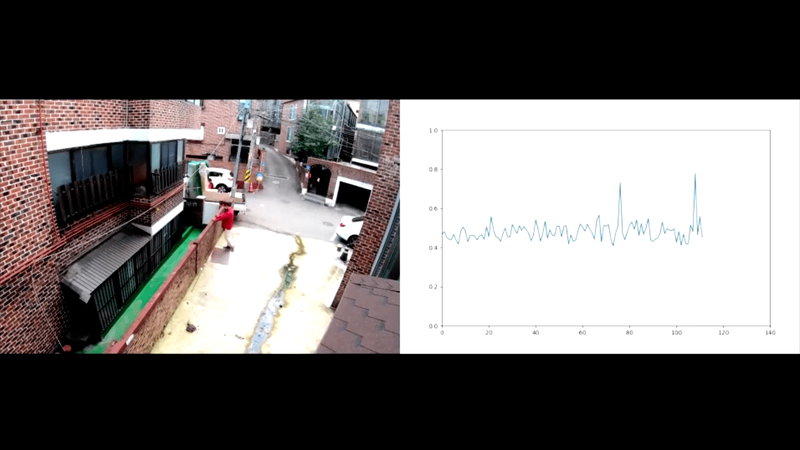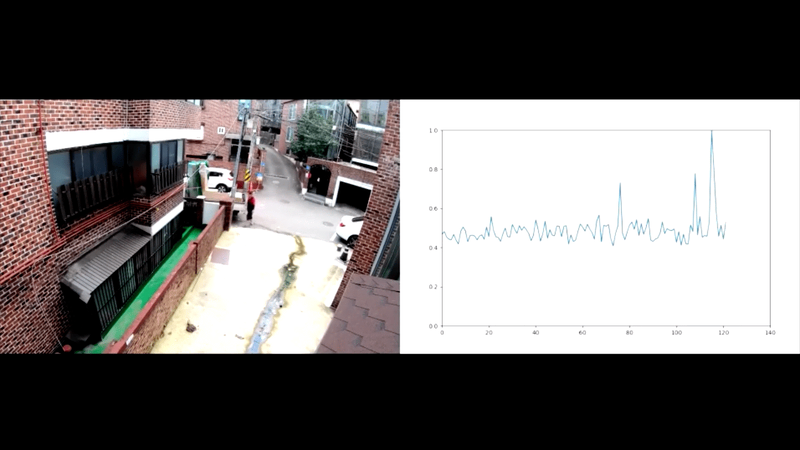
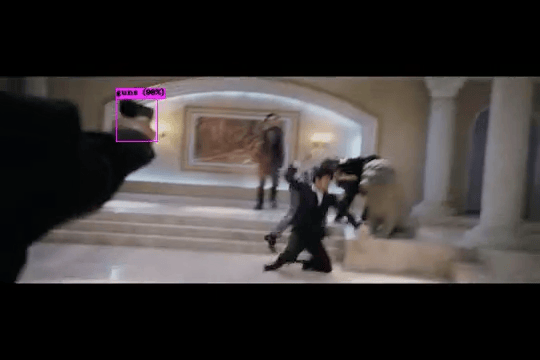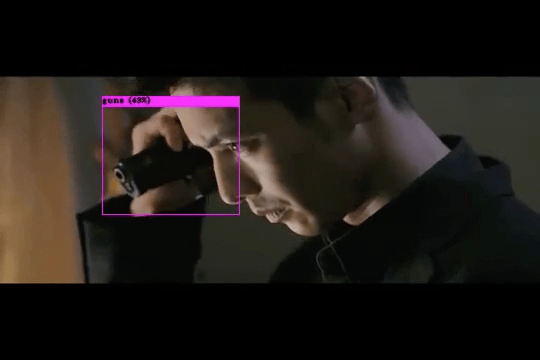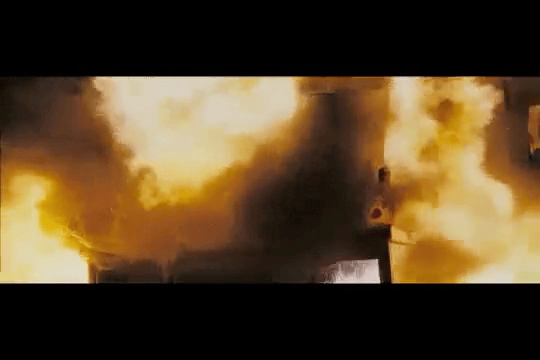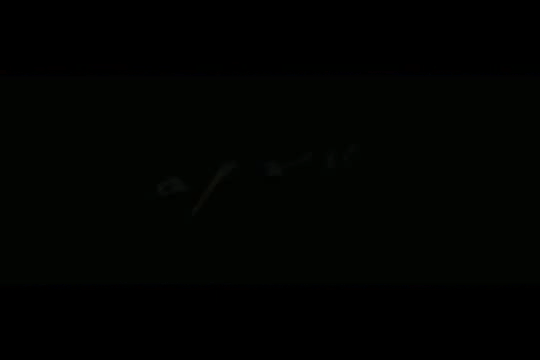
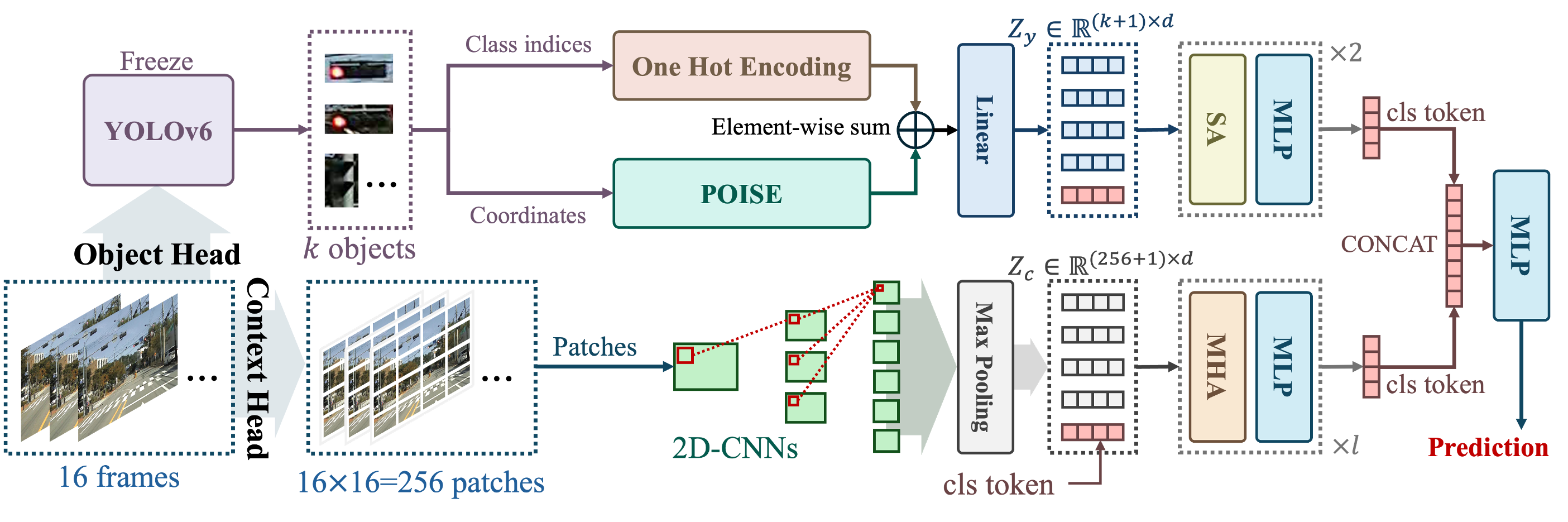
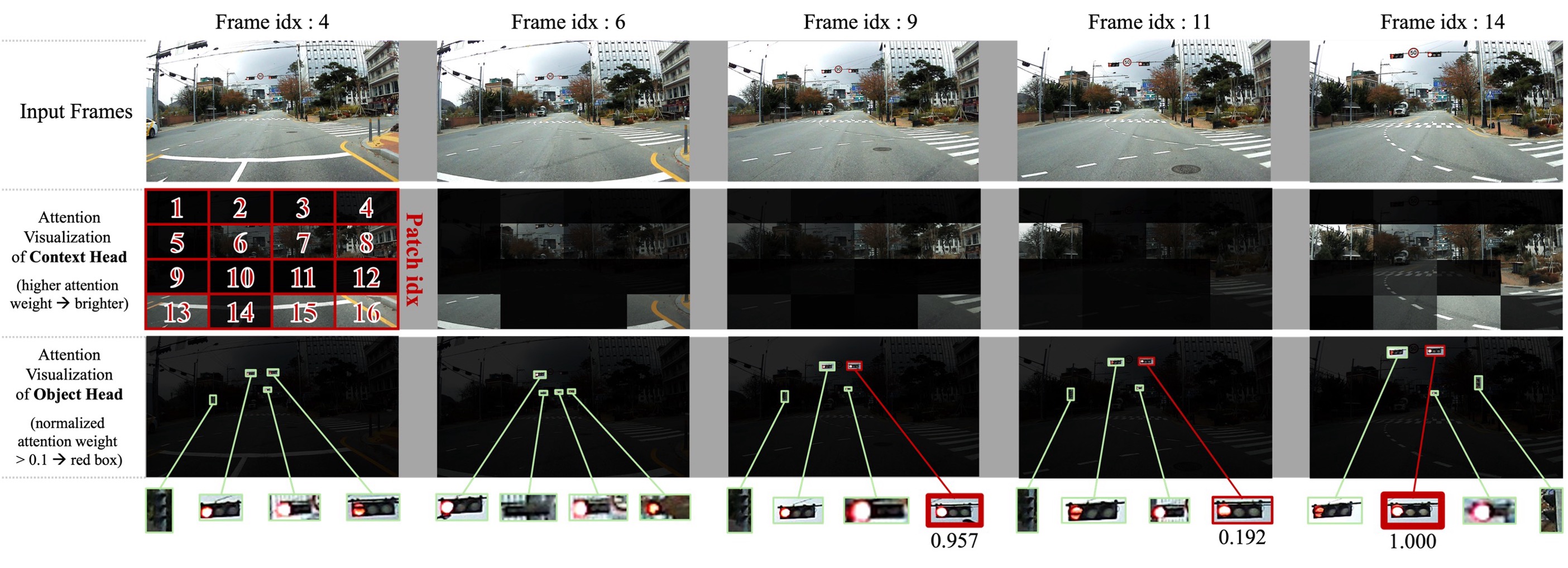
- Dangerous Object Detection and Tracking using YOLO: While anomaly detection in surveillance video is effective for identifying unusual behaviors such as violence, vandalism, abduction, or trespassing, etc., it may not always trigger alerts based solely on the presence of dangerous objects. However, the appearance of weapons, firearms, or other objects that could be used in crimes serves as a crucial indicator of potential danger. This project focuses on fine-tuning the well-known YOLO object detector to identify dangerous objects. This would help enhance surveillance capabilities by identifying potential threats at an earlier stage.

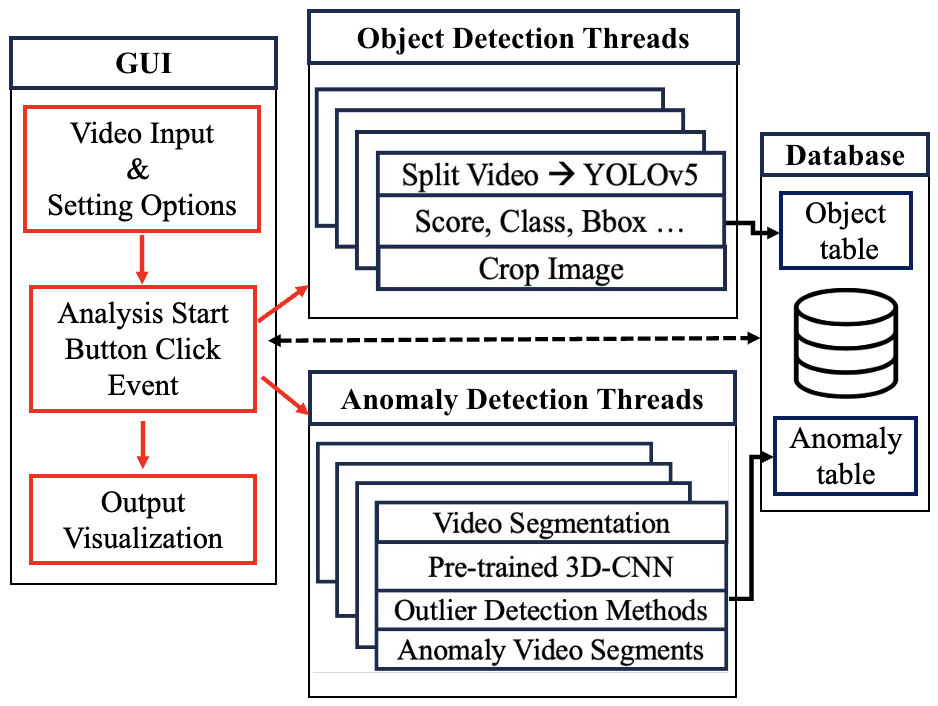
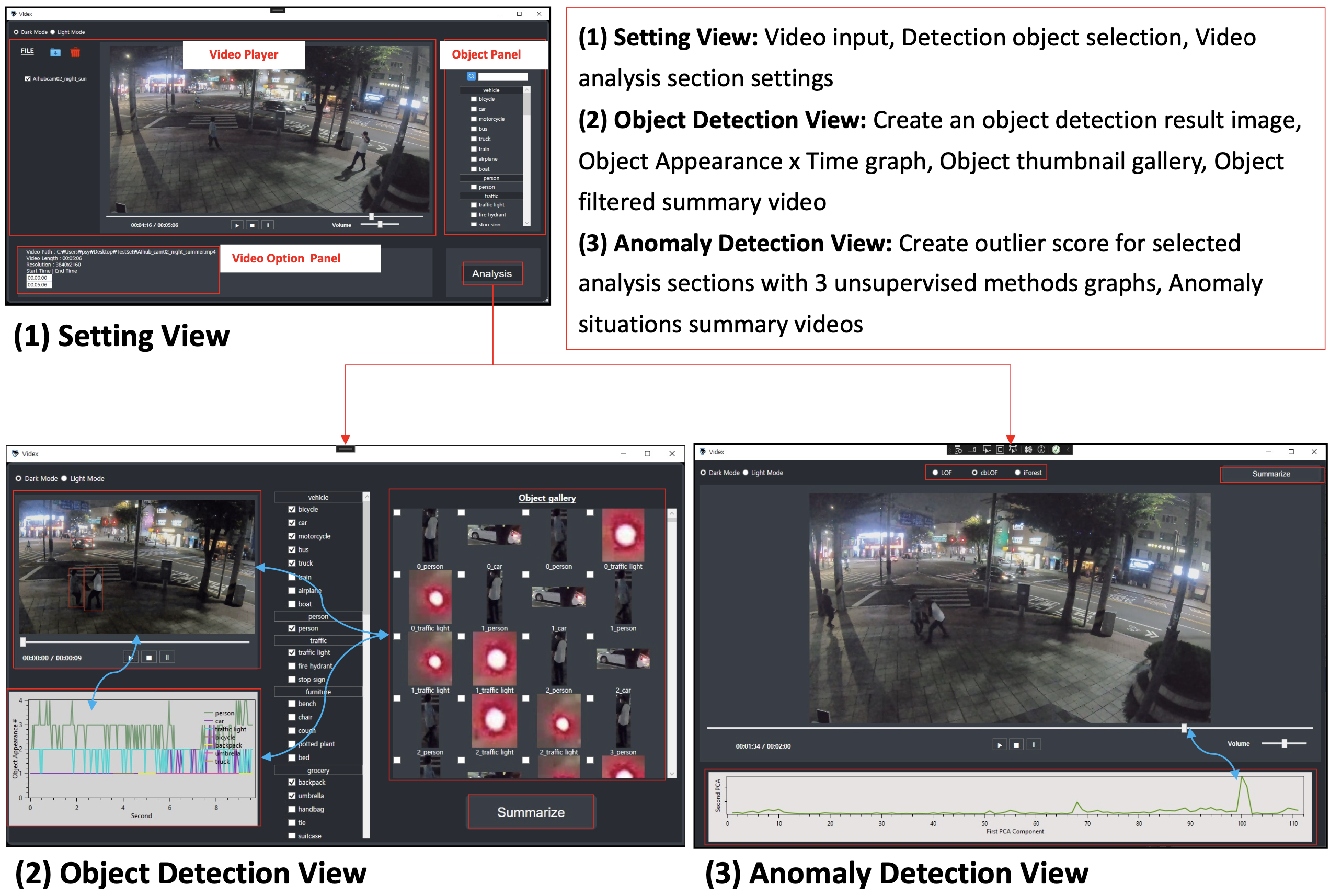
- Video Indexing for Rapid Surveillance Footage Summarization (VIDEX, with GMDSOFT): Alongside anomaly detection and object detection methods, we are developing applications to make the analysis of surveillance footage more efficient. This project involves creating a video indexing system that allows the results of anomaly and object detection to be stored, searched, and navigated easily. The goal is to assist investigators in maximizing their efficiency when analyzing large volumes of video data by providing quick access to critical segments.

- Driving Habit Analysis using Dashcam Videos (with AI-CAR): In some countries including Korea, dashcams are widely used to monitor the surroundings of vehicles. While sensor-based traffic signal violation detection and ADAS (Advanced Driver Assistance Systems)-based lane departure warnings are already familiar, this project focuses on monitoring safe driving, rather than law enforcement. To achieve this, we have developed a Raspberry Pi-based dashcam with wireless connectivity for real time data collection. The system records and analyzes metrics such as lane departure frequency and traffic signal violations, to eventually provide a safety score for drivers based on their behavior.

Battery Remaining Useful Life
Through the analysis of data from Electric Vehicle (EV) Battery Management Systems (BMS), we are developing advanced technology to help users manage their vehicles more predictively and efficiently.
- Range Prediction: *How far can my EV go from here?* Unlike conventional gas-powered vehicles with traditional refueling methods, accurately predicting the range of an EV is crucial for drivers. While all EVs on the market currently provide a range estimate on their dashboards, our research goes beyond these manufacturer predictions. We incorporate driving habits, charging behaviors, and the degradation curve of the battery charge to provide a more accurate and tailored range prediction for users. Our system aims to offer a better and more reliable estimate than what is currently available from manufacturers.
- Future Remaining Useful Life Prediction: *What will the future value of my EV battery be?* The remaining useful life (RUL) of an EV battery not only affects the vehicle's driving range but is also a key factor in determining the overall value of the vehicle. Our research focuses on predicting the future value of EV batteries by analyzing BMS and On-board Diagnostics (OBD) signals. Using time-series modeling techniques, we aim to provide a more precise forecast of the future health and value of the battery, so that users can make informed decisions about their vehicle’s long-term maintenance and value.
Korean Unification Big Data Center (KUBiC)
Handong Global University is committed to her unique motto, "Learn to Share and Change the World". As part of these efforts, at HAIL, we are persistently developing IT-based methodologies and case studies to accelerate reconciliation between South and North Korea.
- Development of the KUBiC search engine: In collaboration with Prof. JC Nam and Prof. Jihyun Park, we have developed and are maintaining a specialized search engine for research literature on North Korean and the Korean unification issues. The KUBiC search engine currently indexes over 30,000 research documents and more than 280,000 related news articles. Registered users have access to features such as online data analysis and visualization. HAIL is responsible for the backend of the search engine, including its design, implementation, and maintenance. Visit KUBiC.
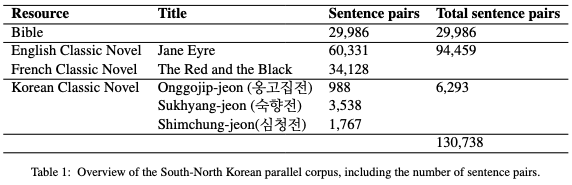
- Development of a South-North Korean parallel corpus and translation models: After over 70 years of separation, South and North Korea have developed differences not only in politics, economics, and culture but also in the language they use. A comparative analysis of dictionaries from both Koreas revealed that 38% of common words and 66% of technical terms differ between the two. This project utilizes a South-North Korean parallel corpus, built from classic literature including the Bible and classic novels, to fine-tune a pre-trained South Korean language model and experiment with bidirectional machine translation models between the two Korean dialects.
- Bias analysis of LLMs on North Korean and unification issues: One of the challenges in deploying machine learning technologies and large language models (LLMs) is the inherent bias within these models. Since the rise of these technologies, our research group has continuously evaluated LLMs by posing questions related to North Korea. Our findings indicate a certain level of bias and unfairness in the responses. This study aims to analyze these biases, both qualitatively and quantitatively, and explore potential guidelines for addressing them during the development of LLMs.